Prueba de SegNet. Imagen: Alex Kendall. Fuente: Universidad de Cambridge.
Dos tecnologías que utilizan técnicas de aprendizaje profundo para ayudar a las máquinas a ver y reconocer su ubicación y el entorno se podrían utilizar para el desarrollo de los coches sin conductor y la robótica autónoma -y se pueden utilizar en una cámara normal o un teléfono inteligente.
Los sistemas funcionan allá donde no lo hace el GPS, e identifican los distintos componentes de un escenario de carretera en tiempo real en una cámara normal o un teléfono inteligente, realizando el mismo trabajo que sensores que cuestan decenas de miles de euros.
Los sistemas, distintos pero complementarios, han sido diseñados por investigadores de la Universidad de Cambridge (Reino Unido) y hay muestras disponibles en línea. Aunque los sistemas no pueden de hecho controlar un coche sin conductor, la capacidad de hacer a una máquina "ver" e identificar con precisión dónde está y lo que está viendo es una parte vital del desarrollo de vehículos y robótica autónomos.
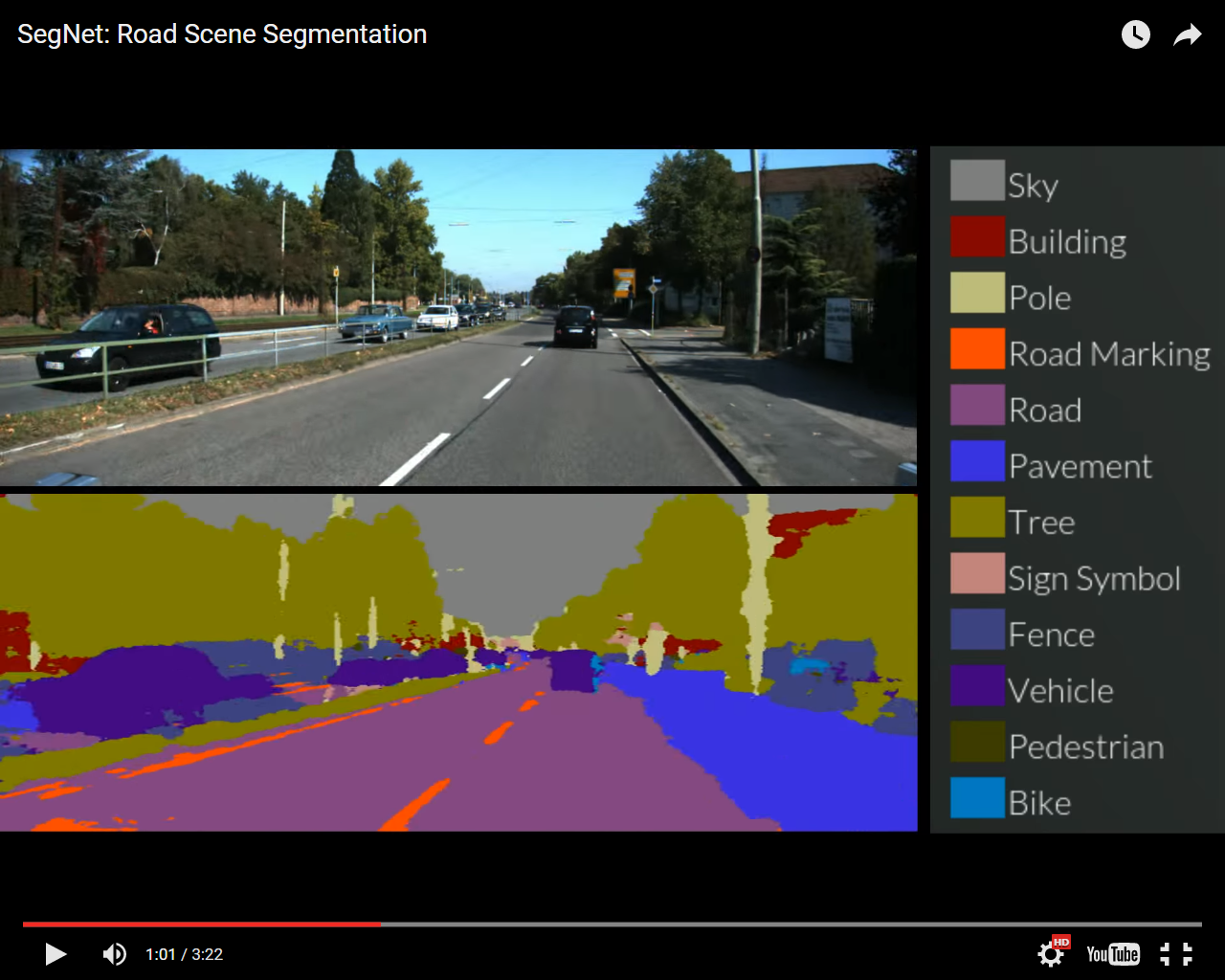
El primer sistema, denominado SegNet, puede tomar una imagen de una escena de la calle que no ha visto antes y clasificarla, ordenando objetos en 12 categorías diferentes -como carreteras, señales de tráfico, peatones, edificios y ciclistas- en tiempo real. Puede tratar entornos luminosos, oscuros y nocturnos, y etiqueta más del 90% de los píxeles correctamente. Sistemas anteriores que utilizaban costosos sensores basados en láser o radar no han podido llegar a este nivel de precisión funcionando en tiempo real.
Los usuarios pueden visitar el sitio web de SegNet y subir una imagen o buscar cualquier ciudad o pueblo del mundo, y el sistema etiquetará todos los componentes de la escena de carretera. El sistema ha sido probado con éxito tanto en carreteras de ciudad como en autopistas.
Aprendiendo con el ejemplo
Para los coches sin conductor actualmente en desarrollo, los sensores de radar son caros -de hecho, a menudo cuestan más que el propio vehículo. En contraste con ellos, que reconocen los objetos a través de una mezcla de radar y LIDAR (una tecnología de teledetección), SegNet aprende con el ejemplo -fue entrenado por un laborioso grupo de estudiantes de grado de Cambridge, que marcaron de forma manual cada píxel de 5.000 imágenes, tardando unos 30 minutos en completar cada una. Una vez que el etiquetado se terminó, los investigadores tardaron dos días en "entrenar" al sistema antes de que se pusiera en acción.
"Es muy bueno reconociendo cosas en una imagen, ya que ha tenido mucha práctica", dice Alex Kendall, estudiante de doctorado en el Departamento de Ingeniería. "Además, podemos afinar el sistema de muchas formas diferentes para que siga mejorando."
SegNet fue entrenado principalmente en carreteras y entornos urbanos, por lo que todavía le queda algo de aprendizaje para entornos rurales, nevados o desérticos -a pesar de que ha obtenido buenos resultados en las pruebas iniciales para estos entornos.
El sistema todavía no está en el punto de poder ser usado para controlar un automóvil o camión, pero podría ser utilizado como sistema de alerta, similar a las tecnologías anti-colisión disponibles en la actualidad en algunos coches de pasajeros.
"La visión es nuestros sentido más poderoso y los coches sin conductor también tendrán que ver", dice el profesor Roberto Cipolla, que dirigió la investigación, en la nota de prensa de Cambridge. "Pero enseñar a una máquina a ver es mucho más difícil de lo que parece."
De niños, aprendemos a reconocer los objetos a través del ejemplo -si se nos muestra un coche de juguete varias veces, aprendemos a reconocer tanto ese coche específico como otros coches similares, como el mismo tipo de objeto. Pero con una máquina, no es tan simple como mostrarle un solo coche y que luego sea capaz de reconocer todos los diferentes tipos de vehículos. Las máquinas hoy aprenden bajo supervisión: a veces a través de miles de ejemplos etiquetados.
Hay tres preguntas claves tecnológicas que deben ser respondidas para diseñar vehículos autónomos: ¿Dónde estoy, qué me rodea y qué hago ahora. SegNet aborda la segunda cuestión, mientras que un sistema separado pero complementario responde a la primera mediante el uso de imágenes para determinar tanto la ubicación como la orientación de forma precisa.
Los sistemas funcionan allá donde no lo hace el GPS, e identifican los distintos componentes de un escenario de carretera en tiempo real en una cámara normal o un teléfono inteligente, realizando el mismo trabajo que sensores que cuestan decenas de miles de euros.
Los sistemas, distintos pero complementarios, han sido diseñados por investigadores de la Universidad de Cambridge (Reino Unido) y hay muestras disponibles en línea. Aunque los sistemas no pueden de hecho controlar un coche sin conductor, la capacidad de hacer a una máquina "ver" e identificar con precisión dónde está y lo que está viendo es una parte vital del desarrollo de vehículos y robótica autónomos.
El primer sistema, denominado SegNet, puede tomar una imagen de una escena de la calle que no ha visto antes y clasificarla, ordenando objetos en 12 categorías diferentes -como carreteras, señales de tráfico, peatones, edificios y ciclistas- en tiempo real. Puede tratar entornos luminosos, oscuros y nocturnos, y etiqueta más del 90% de los píxeles correctamente. Sistemas anteriores que utilizaban costosos sensores basados en láser o radar no han podido llegar a este nivel de precisión funcionando en tiempo real.
Los usuarios pueden visitar el sitio web de SegNet y subir una imagen o buscar cualquier ciudad o pueblo del mundo, y el sistema etiquetará todos los componentes de la escena de carretera. El sistema ha sido probado con éxito tanto en carreteras de ciudad como en autopistas.
Aprendiendo con el ejemplo
Para los coches sin conductor actualmente en desarrollo, los sensores de radar son caros -de hecho, a menudo cuestan más que el propio vehículo. En contraste con ellos, que reconocen los objetos a través de una mezcla de radar y LIDAR (una tecnología de teledetección), SegNet aprende con el ejemplo -fue entrenado por un laborioso grupo de estudiantes de grado de Cambridge, que marcaron de forma manual cada píxel de 5.000 imágenes, tardando unos 30 minutos en completar cada una. Una vez que el etiquetado se terminó, los investigadores tardaron dos días en "entrenar" al sistema antes de que se pusiera en acción.
"Es muy bueno reconociendo cosas en una imagen, ya que ha tenido mucha práctica", dice Alex Kendall, estudiante de doctorado en el Departamento de Ingeniería. "Además, podemos afinar el sistema de muchas formas diferentes para que siga mejorando."
SegNet fue entrenado principalmente en carreteras y entornos urbanos, por lo que todavía le queda algo de aprendizaje para entornos rurales, nevados o desérticos -a pesar de que ha obtenido buenos resultados en las pruebas iniciales para estos entornos.
El sistema todavía no está en el punto de poder ser usado para controlar un automóvil o camión, pero podría ser utilizado como sistema de alerta, similar a las tecnologías anti-colisión disponibles en la actualidad en algunos coches de pasajeros.
"La visión es nuestros sentido más poderoso y los coches sin conductor también tendrán que ver", dice el profesor Roberto Cipolla, que dirigió la investigación, en la nota de prensa de Cambridge. "Pero enseñar a una máquina a ver es mucho más difícil de lo que parece."
De niños, aprendemos a reconocer los objetos a través del ejemplo -si se nos muestra un coche de juguete varias veces, aprendemos a reconocer tanto ese coche específico como otros coches similares, como el mismo tipo de objeto. Pero con una máquina, no es tan simple como mostrarle un solo coche y que luego sea capaz de reconocer todos los diferentes tipos de vehículos. Las máquinas hoy aprenden bajo supervisión: a veces a través de miles de ejemplos etiquetados.
Hay tres preguntas claves tecnológicas que deben ser respondidas para diseñar vehículos autónomos: ¿Dónde estoy, qué me rodea y qué hago ahora. SegNet aborda la segunda cuestión, mientras que un sistema separado pero complementario responde a la primera mediante el uso de imágenes para determinar tanto la ubicación como la orientación de forma precisa.
Localización
El sistema de localización diseñado por Kendall y Cipolla se ejecuta en una arquitectura similar a SegNet, y es capaz de localizar a un usuario y determinar su orientación a partir de una imagen de un solo color en una escena urbana llena de cosas.
El sistema es mucho más preciso que el GPS y funciona en lugares donde el GPS no, como en interiores, en túneles o en ciudades donde no se dispone de una señal GPS fiable.
Se ha probado a lo largo de un tramo de un kilómetro de la calle King's Parade, en el centro de Cambridge, y es capaz de determinar tanto la ubicación como la orientación con pocos metros y unos pocos grados de precisión, que es mucho más que la del GPS -una cuestión vital para los coches sin conductor. Los usuarios pueden probar el sistema por sí mismos aquí.
El sistema de localización utiliza la geometría de una escena para conocer su ubicación exacta, y es capaz de determinar, por ejemplo, si está mirando hacia el este o el oeste de un edificio, aunque las dos partes parezcan idénticas.
"El trabajo en el campo de la inteligencia artificial y la robótica ha tenido mucho éxito en los últimos años", dice Kendall. "Pero lo bueno de nuestro grupo es que hemos desarrollado tecnología que utiliza el aprendizaje profundo para determinar donde estás y lo que te rodea."
"En el corto plazo, es más probable ver este tipo de sistema en un robot doméstico -como una aspiradora robótica, por ejemplo", dice Cipolla. "Pasará tiempo antes de que los conductores pueden confiar plenamente en un vehículo autónomo, pero cuanto más eficaces y precisas podamos hacer estas tecnologías, más cerca estaremos de la adopción generalizada de los coches sin conductor y de otros tipos de robótica autónoma."
Los investigadores presentaron los detalles de las dos tecnologías en la Conferencia Internacional sobre Visión por Computador, en Santiago, Chile.
El sistema de localización diseñado por Kendall y Cipolla se ejecuta en una arquitectura similar a SegNet, y es capaz de localizar a un usuario y determinar su orientación a partir de una imagen de un solo color en una escena urbana llena de cosas.
El sistema es mucho más preciso que el GPS y funciona en lugares donde el GPS no, como en interiores, en túneles o en ciudades donde no se dispone de una señal GPS fiable.
Se ha probado a lo largo de un tramo de un kilómetro de la calle King's Parade, en el centro de Cambridge, y es capaz de determinar tanto la ubicación como la orientación con pocos metros y unos pocos grados de precisión, que es mucho más que la del GPS -una cuestión vital para los coches sin conductor. Los usuarios pueden probar el sistema por sí mismos aquí.
El sistema de localización utiliza la geometría de una escena para conocer su ubicación exacta, y es capaz de determinar, por ejemplo, si está mirando hacia el este o el oeste de un edificio, aunque las dos partes parezcan idénticas.
"El trabajo en el campo de la inteligencia artificial y la robótica ha tenido mucho éxito en los últimos años", dice Kendall. "Pero lo bueno de nuestro grupo es que hemos desarrollado tecnología que utiliza el aprendizaje profundo para determinar donde estás y lo que te rodea."
"En el corto plazo, es más probable ver este tipo de sistema en un robot doméstico -como una aspiradora robótica, por ejemplo", dice Cipolla. "Pasará tiempo antes de que los conductores pueden confiar plenamente en un vehículo autónomo, pero cuanto más eficaces y precisas podamos hacer estas tecnologías, más cerca estaremos de la adopción generalizada de los coches sin conductor y de otros tipos de robótica autónoma."
Los investigadores presentaron los detalles de las dos tecnologías en la Conferencia Internacional sobre Visión por Computador, en Santiago, Chile.